



職稱 : 教育研究所助理教授
學歷 : 國立成功大學統計博士
專長 : 巨量資料探勘、網路社群資料分析、統計方法
分享話語: 比起大自然的力量,人的力量微不足道; 尊重自然,還山河於天地。

研究描述
巨量資料(Big data),或稱大數據、海量資料,指的是所涉及的資料量規模巨大到無法透過人工,在合理時間內達到擷取、管理、處理、並整理成為人類所能解讀的資訊。2012 年 Doug Laney 對大數據做出一個全新的定義:「Big data is high volume, high velocity, and/or high variety information assets that require new forms of processing to enable enhanced decision making, insight discovery and process optimization. 巨量資料是大量、高速、及具類型多變的資訊資產,它需要全新的處理方式,去促成更強的決策能力、洞察力與最佳化處理。」 ( 詳見圖一 )
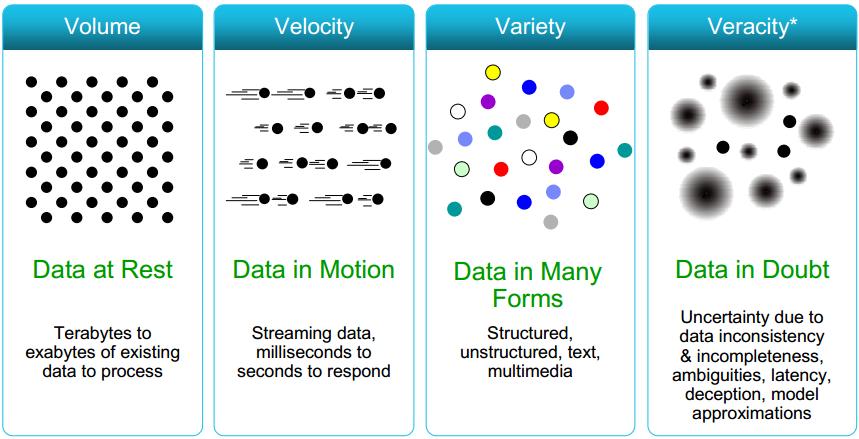
圖一 : 巨量資料四大特色 -- 大、快、雜、移
我目前從事的研究在於資料探勘與文字探勘,我所進行的文字探勘研究技術大部分來自資料探勘的手法,透過字詞矩陣轉化為使用資料探勘手法來進行分析。我在中文斷詞與網路爬蟲的研究,將整合為一個Leo System,包含Leo-Say,Leo-SQuirreL:
(1) 中文斷詞 Leo-Say: 顧名思義就是想辦法讓機器發現新詞彙,及認識中文詞彙,例如:「佛跳牆:名詞」是一種食物,基本的電腦機器懂【佛:名詞】、【跳:動詞】、【牆:名詞】,透過認識中文詞彙,Leo-Say就會懂有一種食物叫做【佛跳牆】,當機器判讀文章內容有【佛跳牆】字眼時,機器可以正確判斷內容是談論食物,而不是討論【佛】學、或運動行為【跳牆】等 ( 詳見圖二 )。除此之外,讓機器認識發現流行用語也是一件很重要的事,例如:【了不了】、【喘共】等網路詞彙。這方面,我最大的研究內容是文件的主題模式(Topic Model)研究,主題模式是一種透過機器學習方法針對文件內容(Text Content)分析,讓機器能判別文件內容所討論的主題,或者生成一篇特別指定主題文章的統計方法。主題模式需要一大批的訓練文件,作為學習分類的標準。所以,中文斷詞做得好,後續主題模式分析才能有好文件分類的正確率。

圖二 : 中文斷詞與新建詞庫識別字典(TW-Food.dic)檔
(2) 網路爬蟲 Leo-SQuirreL: 就是由local端派出收集資料目標網站的網路爬蟲蜘蛛機器到各處收集目標資料 ( 詳見圖三 ),所以我的研究資料庫是整個網路 (這是所謂無招勝有招,因為我探勘的資料量遠遠大於正規的資料庫,我的研究沒有資料庫(嚴格說是分散式資料庫,或散落各處的大型正規資料庫)--只有資料海)。我的研究成果,可以用於主題新聞分析,社群媒體網站FaceBook、Twitter、Moodle 教學平台,或知名旅遊網站 TripAdvisor 評論等,可以進行巨量資料的資料探勘,或社群網路資料分析等。這研究的限制在於【探勘資料是否有目標資料庫】,及【網路防火牆的設置強度】。

圖三 : 自建網路爬蟲示意圖